나는 원래는 컴퓨터 비전을 연구 했지만 최근 테이블 형태의 빅데이터 처리나 비즈니스 인포메틱스와 관련된 공부를 시작했다. 실제 이윤 창출에는 이쪽이 더 생산성 있는것 같다. 이것은 순전히 나의 개인 공부 기록이니 참고 정도로 활용하시면 되겠다. 많은 인터넷 자료들과 영상들을 참고하였고 그중에서도 카카오 추천팀의 자료를 많이 참고했다.
좋은 글과 참고 코드를 공개하여 주신 카카오 추천팀에게 많은 감사를 드린다.
1. 콘텐츠 기반 필터링
- 어떤 데이터?
데이터의 특징이 기존 소비 패턴을 지속적으로 따르는 경우
ex) 좋아하는 작가의 만화를 계속 본다. 좋아하는 브랜드의 옷을 자주 구매한다 등.
이럴경우 기존 아이템의 정보를 활용해 추천하는 콘텐츠 기반 필터링이 적합
- 뭐라고?
그러니까, 사용자가 선택한 경험이 있는 아이템(높은 평점을 매긴 영상, 구매한 물건 등)과
유사한특징을 가지고 있는 아이템을 추천한다.
나와 유사한 사람이 선택한 아이템을 추천하는 협업 필터링과는 다르다.
- Strong and Weak?
사용자들의 데이터가 필요 없다. 아이템과 아이템간의 관계만 연산하면 되기 때문에
아이템의 정보에 대한 태깅만 필요하다. 사용자가 클릭했던 상품과 연관된 아이템을 뿌려주면 된다.
하지만 사용자가 오래 사이트를 이용했을 경우, 해당 데이터들을 활용한 협업 필터링보다 성능이 떨어진다는 인식이 있다.
때문에 소비 이력이 적은 아이템, 또는 사용자 데이터가 적을 때 제한적으로 활용.
- 어떻게 한다고?
때문에, 각 아이템간 유사도를 연산 할 수 있어야함.
각 아이템에 대한 정보 태그를 기록하고 원-핫 인코딩이나 임베딩 등의 방법을 활용해
벡터화 해서 벡터 유사도를 측정하면 된다.
그리고 벡터 유사도로 sorting해서 화면에 뿌려주면 된다.
벡터화 할때에는 각 데이터의 유형에 따라서 다른 방법과 전처리를 해야함.
아래의 전처리 방법은 앞으로 다루어볼 문제들이다.
- 숫자형 데이터들은 normalization이나 standalization을 해야한다.
- 결측치도 핸들링 해야한다. (필터를 활용한 예측, 분포를 활용한 샘플링, 데이터 먼징 등)
- 문자열은 대부분 범주형일 것이기 때문에 0~1사이로 핸들링 한다.
- 만약 상품 설명에 대한 자연어일 경우 자연어 모델을 이용해 임베딩을 뽑아낸다.
(BERT, GPT 등을 활용해 자연어 임베딩 추출 후 유사도 활용 등, word2vec 할바엔 이게 나을듯, 최근엔 한국어 임베딩 모델도 많이 나오고 있음)
- 상품 추천 이라면 이미지를 활용하는 방법도 있음, 이경우 pre-trained CNN을 활용해 단순 이미지 피처를 뽑아내
활용할 수 있음. 요즘 각광받는 초거대 비전-언어 대조 학습으로 사전학습된 모델을 활용하면 좋을듯.
- Similarity metric
(1) Cosine similarity
일반적으로 활용할 수 있는 가장 기본이 되는 벡터 유사도 측정 방법.
추가 정보는 아래를 참고하시길.
1) 코사인 유사도(Cosine Similarity)
BoW에 기반한 단어 표현 방법인 DTM, TF-IDF, 또는 뒤에서 배우게 될 Word2Vec 등과 같이 단어를 수치화할 수 있는 방법을 이해했다면 이러한 표현 방법에 대 ...
wikidocs.net
(2) Jaccard vector similarity
CVPR2021에서 처음 제안된 vector similarity.
간단히 설명하자면 각도 뿐만 아니라 거리도 반영된 유사도를 획득할 수 있다.
구현 : https://github.com/khm159/jaccard-vector-similarity
GitHub - khm159/jaccard-vector-similarity: this is unofficial implementation of Jaccard Vector Similarity
this is unofficial implementation of Jaccard Vector Similarity - GitHub - khm159/jaccard-vector-similarity: this is unofficial implementation of Jaccard Vector Similarity
github.com
(3) 피어슨 상관계수(Pearson correlation coefficient)
https://en.wikipedia.org/wiki/Pearson_correlation_coefficient
그냥 두 벡터간 normalization후 cosine similarity를 구하는 것으로 이해해도 무방.
-1 ~ 1 사이의 값으로 나오고 absolute value 는 정확히 1이 되기 때문에 similarity 로 활용 가능.
엄범님이 잘 정리해 놓으셨다.
2. 협업 필터링
- 뭐라고?
어떤 소비자가 어떤 상품 내지는 아이템을 소비한 이력이 있을 때, 유사한 소비 패턴을 보이는 다른 소비자가 좋아하는 아이템을 좋아할 가능성이 높다라고 가정한다. 사용자가 함께 소비하는 아이템을 추천할 수 있기 때문에 충분한 데이터를 확보할 수 있을경우에 더 정확한 추천이 가능하다.
- Strong and Weak?
사용자와 아이템간의 상호작용을 기반으로 추천한다. 때문에 컨텐츠 기반 추천 방식에서 유사도 점수가 낮은 아이템도 소비 패턴으로 발견되어 추천될 수 있다. 하지만 충분한 이용 데이터가 쌓이기 전에는 서비스에 도입하기 어렵다.
모델 학습이 필요하지만, 추론시에는 적은 부하가 걸린다.
- 어떻게 한다고?
메모리 기반의 방법과 모델 기반의 방법이 존재한다.
(1) 메모리 기반의 방법
소비 이력을 저장해 놓았다가 조회하는 방식으로 구현되는 협업 필터링.
어떤 아이템에 대한 rating이 필요하거나, 소비자의 ui에 추천 아이템을 뿌려줄 때
소비자의 패턴과 유사한 패턴을 보인 다른 소비자들의 데이터를 조회하여 추정한다.
전통적인 방식이다.
(2) 모델 기반의 방법
단순히 이전 데이터를 조회하는 방식이 아니라
통계적 모델이나 딥 러닝을 이용해 예측하는 방식
latent factor 방식이나 classification/regression을 수행, 또는 딥러닝을 이용한 방식이 있다.
- latent factor
기본적으로 벡터 유사도를 기반으로 한다는 점에서는 컨텐츠 기반 방식과 동일한 것으로 보임.
하지만 아이템-아이템간 벡터 유사도를 구하는 것과는 달리, 사용자-아이템간 유사도를 구하는것이 다른점이다.
대표적인 방법은 Matrix factorization이다.
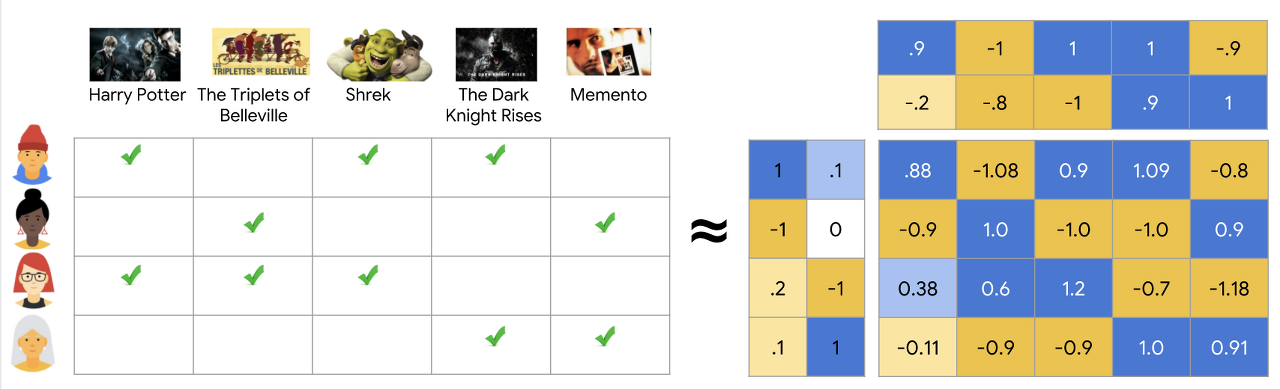
factorization은 분해를 의미하며 여기서 matrix 는 사용자와 아이템 간의 관계를 의미한다.
사용자가 어떤 아이템들에 대해 매긴 rating 정보가 있을 때 이를 사용자별로 matrix 형태로 만들 수 있다.
사용자는 일부 데이터에 대해서만 rating 하기 때문에 대부분 sparse 한 데이터를 획득할 것이다.
matrix factorization은 이를 찾는 과정이라고 볼 수 있다.
많은 내용들이 있는데 간단히 말하면
rating matrix = M_r = (num of user * num of item)
사용자의 latent matrix를 정의하고 (M_u = num of user * D)
아이템의 latent matrix를 정의해서 (M_i = num of item * D)
M_u^T*M_i=M_r 과 같이 하나 transpose 시켜서 곱해주어서 같은 값이 되도록 업데이트 시키면 된다.
즉 원래의 rating 이 되도록 latent matrix를 학습하면 M_u와 M_i가 학습될거고
이 D를 이용해 사용자가 rating 하지 않은 아이템에 대해서도 예측이 가능하다!
그리고 데이터가 쌓이면 쌓일수록 편향이 없다면 더 좋은 latent matrix가 얻어진다.
rating matrix를 M_u와 M_i로 분해하는 방법이기 때문에 다양한 matrix decomposition 방식을 활용할 수 있음.
예를들자면 SVD
https://en.wikipedia.org/wiki/Singular_value_decomposition
Singular value decomposition - Wikipedia
From Wikipedia, the free encyclopedia Jump to navigation Jump to search Matrix decomposition Illustration of the singular value decomposition UΣV⁎ of a real 2×2 matrix M. Top: The action of M, indicated by its effect on the unit disc D and the two cano
en.wikipedia.org

위 그림을 기준으로 M을 rating matrix라고 가정한다면 SVD 알고리즘을 통해서 U와 V로 분해할 수 있음
SVD를 통해서 이 둘은 orthogonal 하기 때문에 서로 다른 특징으로 잘 분리가 가능함.
많은 방법들을 사용할 수 있음.
더 자세한 내용은 다른 포스팅으로 다룰 예정.
사용자 데이터가 없어도 우선적으로 적용할 수 있는 방법은 콘텐츠 기반 추천이다. 다음에는 이 방법에 대해서 더 자세히 알아보겠다.
Reference
[1] 카카오 추천팀 공개 레포지토리
[2] 카카오 AI 추천: 카카오의 콘텐츠 기반 필터링
[3] 카카오 AI 추천: 협업 필터링 모델 선택 시의 기준에 대하여
'데이터 분석 > 머신러닝' 카테고리의 다른 글
| [머신러닝] 통계적 접근과 데이터 분석 (0) | 2022.07.03 |
|---|