- Unsupervised Domain Adaptation 기법을 Object Detection 에 적용하다.
- Intermidiate domain을 생성하여 점진적으로 Adaptation 한다.
Method
1. Object Detection Network
사용한 네트워크 : Faster R-CNN, Encoder Network E로 정의
이미지를 I로 정의할 때 feature map E(I)는 RPN과 ROI classifier에 입력된다.
loss function은 Faster R-CNN과 동일.
2. Domain Discrimonator
일반적인 Unsupervised Domain Adaptation 방법들과 같이, Domain Discriminator를 붙였다.
입력 featuremap이 source에서 왔는지 target 에서 왔는지 분류하는 module로 objective는 source 인지 target인지 분류할 수 없는 random classifier가 되는 것이다. 그렇게 된다면 domain invariant feature를 featur extractor가 생성할 수 있다.
분류 네트워크와는 다른것은, Object detection 문제이기 때문에 픽셀레벨 BCE loss를 적용했다는 점이다.
D는 Discriminator를 의미하며, 입력 featuremap과 동일한 spatial size의 피처맵을 생성한다. activation 은 sigmoid.
기존 domain discriminator의 loss를 그대로 픽셀레벨로 확장하였다. 단순히 모두 더한다.
d는 domain label로서, source일 때에는 0, target일 때에는 1이다.
목표는 random classifier, P=0.5.
domain을 너무 잘 분류하게 되면. target일 때는 D(E(I))=1, D(E(I))=0 이 된다.
target에 대한 예측값은 낮춰야 되고, source에 대한 예측값은 높여야 한다.
입력 데이터가 target일 때
입력 데이터가 source일 때
adversarial learning을 위해서 GRL(Gradient Reversal Layer)을 추가한다.
Discrimination loss를 maximization 하는 방향으로 gradients를 역전 시킴으로 써 adversarial learning의 목적함수를 최적화 한다.
Unsupervised 이기 때문에, Source 에 대해서만 Detection loss를 준다. 거기에 Source-Target pair에 대한 discrimination loss가 추가된다.
크게 별다른 건 없다. 논문의 메인 아이디어는 아니다.
3. Progressive Adaptation
논문의 메인 아이디어 2개의 stage 로 구성되어 있다.
Intermediate domain 샘플을 생성한다.
[Adaptation Process]
CycleGAN을 이용해 Intermediate domain 샘플을 생성한다.
- Stage 1
S -> F(합성된 데이터) 로의 pixel level discrepancy minimization
- Stage 2
F-> T 로의 pixel level discrepancy minimization
[Weighted Supervision]
생성된 이미지의 퀄리티는 좋을수도 있고 나쁠수도 있다.
outlier들 때문에 domain discrepancy가 더 커질 수도 있다.
> F와 T간의 distribusion distance를 기반으로 한 weighting 전략을 통해 부정적인 효과를 상쇄하려 시도.
Target과 먼 distribution을 가진 F의 outlier들에 대해서는 적은 가중치를 준다.
weight는 또 다른 domain discriminator의 output score를 사용했다.
Dcycle은 CycleGAN에서 생성된 이미지의 Domain 을 분류하는 또 다른 discriminator다.
그동안 Action Recognition을 위한 모델 구조는 크게 2D CNN과 3D CNN을 이용한 구조로 발전되어 왔다. 3D CNN은 3D convolution 커널을 사용하기 때문에, 복수의 프레임을 고려할 수 있으므로 spatio-temporal feature extraction이 가능하다. Action Recognition은 시간축으로 사람의 행동이 진행 되기 때문에, spatio-temporal feature learning이 중요하다. 때문에 3D CNN을 이용한 I3D, C3D, P3D 의 구조를 이용한 모델들이 많이 사용되고 있다. 하지만 3D CNN은 커널의 채널이 하나 더 존재 하기 때문에 모델 연산 속도가 느리다. 또한 파라미터가 더 많기 때문에, 학습이 일반적으로 더 어려운 특징이 존재한다.
이를 해결하기 위해서, 2D CNN으로 프레임의 특징을 추출하고 추출된 벡터들 간의 temporal modeling 능력을 키우는 시도들이 있었고, 3D CNN의 convolution 연산 방식을 변경하거나, 2D convolution과 3D convolution을 융합하는 등의 시도를 통해 3D CNN의 efficiency를 향상시키는 시도들이 존재했다.
어떤 모델을 사용할 지는 실제 문제를 푸는데 중요한 이슈이다. 몇몇 벤치마크 데이터셋들이 존재하기는 하지만, 이들의 성능을 객관적으로 비교하기란 어렵다. 코드 공개가 되어 있지 않거나, 같은 벤치마크 데이터셋에 대해서 성능평가가 진행되지 못한 경우가 많기 때문이다. 본 논문에서는 다양한 2D/3D CNN SOTA 모델들을 같은 환경에서 비교/분석한 결과를 제공하며 그동안 간과 되었던 요소들에 대한 상세한 분석을 하였다. 또한 현재 논문을 accept시키기 위해서만 연구를 진행하는 세태를 비판하기도 한다. 앞으로의 모델 설계 및 활용에 좋은 참고점이 되길 바라며 논문을 선택하게 되었다.
뭐하는 논문인가 :
그동안 많은 발전을 이루었던 2D/3D CNN based Action Recognition Approaches들을 동일한 실험 환경에서 비교/분석
논문이 고민해 보고자 했던 내용 :
그동안 많은 2D/3D CNN 구조들이 Action Recognition의 성능을 향상시키기 위하여 제안되었다. 이들은 Something-Something과 같은 제스처 인식 에서 부터 Kinetics 데이터셋과 같은 몸 전체가 보이는 행동인식 또는 ego-centric 영상에 이르기 까지 다양한 벤치마크 데이터셋에서 성능 평가가 이루어 졌다. 하지만 "성능 향상"이 메인이 되다 보니, 아직까지 몇가지 의문점에 대해 면밀한 분석이 이루어지지 못했다.
1. 이러한 "성능 향상"을 이룩했다는 것은 더 나은 "Spatio-Temporal Representation"을 학습했다는 의미이기도 하다. 그렇다면 이것이 어떻게 가능했는가?
2. 2D CNN 기반의 모델과 3D CNN 기반의 모델중 어느것이 더 뛰어난가? 벤치마크 데이터셋 마다 우수한 성능을 가진 구조가 다르고, 평가된 데이터셋 자체도 다른 경우가 많다.
이렇게 되버린 원인 :
1. 이미지 분류에서는 ImageNet이라는 반드시 사용 되어야하는 벤치마크 데이터셋이 존재한다. 하지만, Action Recognition의 벤치마크 데이터셋들은 일정부분 bias 가 존재한다. 예를 들자면, 가장 널리 벤치마크 데이터셋으로 사용되는 Kinetics 데이터셋은 Spatial modeling에 대한 bias 가 존재한다. 때문에 Temporal modeling 능력이 일부 부족하더라도 뛰어난 Spatial modeling 만으로도 더 높은 성능달성이 가능할 수 있다는 문제점이 존재한다.
주석 : 왜냐하면, 유튜브에서 수집 되었기 때문에, 수집되는 과정에서 크롤링으로 키워드를 검색 해서 수집했기 때문에다. 예를들면 "수영하기"는 거의 대부분 수영장에서 수영하는 것이 들어있을 테고, "서핑하기"는 대부분 바다에서 서핑하는 것이 포함되어 있을 것이다. 때문에 사람 부분의 정보가 없더라고 이런 장면의 장소 정보를 통해서도 충분히 모델이 판단을 내릴 수 있는 행동들이 존재하기 때문에, 모델이 학습된 뒤에는 이러한 spatial 정보에 기반하여 판단할 가능성이 높다. 이 문제에 대해서 더 자세히 다루었던 논문을 아래에 소개드린다. 링크는 아카이브 페이퍼로 달아 두었다. 극단적으로 사람영역을 모두 제로 패딩하고도, 오로지 배경과 물체와 같은 context 정보 만으로도 분류할 수 있는 행동들이 존재하며, 이런 샘플들로 학습 및 최적화 된 모델구조는 Temporal modeling 보다는 Spatial modeling에 집중한 구조일 수 있다는 것이다.
from : Mimetics: Towards understanding human actions out of context
2. 현재 논문이 accept되는 구조가 문제다. 단순히 "SOTA 달성"이 가장 큰 임팩트를 가지게 된다. 때문에 모델이 왜 그렇게 동작하는가, 어느 부분이 더 우수한가 에 대한 면밀한 분석이 부족한 경우가 많다. "블랙박스"화가 되고 있다.
3. 또한 논문이 accept되는 것이 목표이기 때문에, 자신들에게 유리한 방향으로 실험을 진행하는 경우가 많았다. 달리 말하면 fair comparison 측면에서 부족한 면이 많았다.
예를 들자면, Inception V1을 백본으로 사용하는 I3D 모델이 Action Recognition의 "성능측정기" 역할-논문의 표현을 빌리자면 "Gatekeeper"-을 많이 하고 있으며, 많은 모델들이 Incepcion V1을 백본으로 사용하는 I3D 모델의 성능보다 우수함을 강조하며 I3D 모델보다 더 좋은 구조라고 주장하고 있다. 하지만 실제로 더 우수한 ResNet50을 백본으로 사용하는 I3D와의 성능 비교에서는 밀리는 모습을 보이는 경우가 있다. Figure 1은 이런 경향을 단적으로 설명하고 있다. Kinetics-400에 대한 성능 측정 결과를 그림으로 나타내고 있다. I3D-R50의 성능이 I3D-Inception보다 4%이상 더 높은 것을 알 수 있는데, I3D-R50과 비교하면 기존 나와있는 모델들 중 I3D 보다 더 좋다고 한 모델들의 성능이 I3D-R50보다 낮은 것을 알 수 있다. 이는 논문이 accept되기 위해 더 유리한 figure와 table을 그리려다 보니 발생된 결과로 보인다.
주석 : figure1에 나와 있는 몇몇 논문들은 타겟하고 있는 바가 다르기 때문일 수 있다. TSM의 경우에는, Accuracy 보다는 Efficiency에 초점을 맞춘 구조이다. R(2+1)D 와 ECO 역시 마찬가지.
4. Evaluation Protocol이 다양하다. 이는 자신의 모델에 더 유리한 방향으로 성능을 측정했기 때문이다.
주석 : 실제로 공개된 코드들을 보면, evaluation 과정이 제각각인 경우가 많다. 명확한 설명이 없는데 코드 공개도 안한경우도 있다. 뒤에서 더 다루어 본다.
논문의 Contributions :
1. 다양한 2D/3D CNN SOTA 모델들을 구현한 통일된 프레임워크 제공(코드 공개)
2. Spatio-Temporal Analysis
3. I3D 이후 I3D 보다 더 뛰어나다고 했던 구조들과 I3D 와의 공평한 비교결과 제공.
비교결과 아직까지도 I3D는 "성능" 측면에서 다른 구조들과 경쟁할만 하며, 최근 구조들은 성능 보다는 efficiency에 초점을 맞추고 있다라는 점을 분석함.
Kinetics-400과 UCF-101, HMDB-51은 유튜브 영상이나 영화 등에서 수집되었다. 뷰 포인트가 다양하고 사람의 몸이 보인다. 하지만 Something-something은 ego-centric 영상이고, jester는 사람의 상체만 나오며 제스처 인식 영상이다. 때문에 Kinetics 에서 잘되는 모델이 Something-something이나 jester에서 잘되리라는 보장은 없다.
이를 해결하기 위해서, 본 논문에서는 모두 같은 데이터셋에 대해 성능을 평가했다.
본 논문은 2015년 부터 2020년사이에 SOTA를 달성했던 37개의 논문들에 대한 통계를 아래와 같은 4개의 측면에서 비교/분석 하였다.
1. Backbone :
70%에 이르는 모델들이 서로다른 Backbone을 사용하고 있다. 때문에 제안된 모델구조가 이전 구조들과 Temporal modeling 측면에서의 장점이 어느것인지 에 대한 명확한 비교 분석이 어렵다. 대부분의 모델들이 Backbone을 ResNet50을 사용하고 있지만, I3D 모델과 비교할 때에는 Inception V1 모델을 사용하고 있다.
2. Input Length :
대부분의 논문들이 ablation study를 이용해서 자신의 모델에 최적화된 frame 수를 사용한다. figure 2 를 보면, 약 80%의 논문들이 서로 다른 길이의 프레임을 사용했음을 알 수 있다. 그런데 보통은 제안된 모델만 이 ablation study를 한다. 많이 비교대상으로 삼는 I3D 도 이 과정을 거쳐서 비교 해야한다.
주석 : 보통 처음에 I3D 모델과(그것도 백본이 더 안좋은) 자신의 모델을 비교 해 더 우수한 모델임을 보이고, 그다음에는 자기 모델에 대해서만 하이퍼파라미터 튜닝 실험결과를 제공한다. 그리고 최종적으로 가장 잘나온 성능으로 SOTA 달성했다고 이야기한다. 실제로는 동일한 evaluation protocol에서 동일 백본의 I3D 모델이 더 우수할 수도 있다.
3. Training Protocol :
GPU의 메모리 사이즈가 기술의 발전에 의해 점점 커지고 있고, GPU의 연산 속도가 점점 빨라지기 때문에 더 큰 배치에에서 더 많은 epoch을 같은 시간에 학습할 수 있게 되었다. 그리고 deep learning 라이브러리의 개선 때문에도 성능이 변할 수 있다(필자는 실제로 그런 경험이 있다). 옛날 모델들도 현재 환경에서 같이 학습 및 평가될 필요가 있다. 알고보니 여전히 더 좋은 구조였을지도 모르기 때문에.
또한, pre-train도 같은 weights로 초기화 해서 비교해야 한다. 어떤 모델은 pre-train을 하지 않았고, 어떤 모델은 ImageNet pretrained 모델을 사용했고, 어떤 모델은 Sports1M을, 어떤 모델은 Kinetics로 pre-trained 되었기 때문이다. 또 같은 데이터셋으로 사전학습했더라도, 서로 다른 weights를 가질 수도 있기 때문이다. 실제로 60%의 모델이 서로 다른 pre-training approach로 학습 되었다.
4. Evaluation Procotol :
여러 Action Recognition 논문을 읽다보면, 가장 모호한 부분이 바로 이 부분이다.(고개를 갸웃하는 경우가 많다.) 당연히 한 동영상에는 하나의 출력값으로 비교해야 할 텐데, 어떤 논문은 하나의 동영상을 몇개의 클립으로 잘라서 결과를 앙상블 한다거나 하는 방법을 쓰기도 한다. 사실은 성능이 비슷하거나 낮은데 이런 방법으로 추가적인 성능향상을 이루어서 SOTA를 달성했을 가능성도 존재한다. 같은 Protocol에서 비교되어야 한다. (진짜 최고다...)
Comparison between 2D-CNN and 3D-CNN
본 논문에서는 널리 사용되는 2D CNN 및 3D CNN 구조를 앞서 언급한 측면에서 비교 분석하려 한다.
I3D나 ResNet3D 는 전체가 모두 3D CNN인 반면에, S3D나 R(2+1)D는 기존 3D Convolution을 변경하여 efficiency 향상을 노린 모델로 temporal 1d conv를 도입해 실제로는 2D CNN에 가까우나 구현 코드가 3D convolution으로 되어 있으므로 3D CNN으로 분류 하였다.
TSN은 처음 코드가 공개된 이후로 이후 수많은 SOTA 모델의 코드 베이스가 되었다. I3D역시 pre-train 모델과 코드를 공개하여 다양한 모듈의 기초 및 백본으로 널리 사용되었다. 다른 모델들도 마찬가지. 때문에 선정 되었다. Slowfast는 논문도 잘 쓰여졌고, 성능도 좋기 때문에, SOTA 네트워크로서 사용되었다.
논문에서는 잡다한것들을 제거하고 공평한 비교를 위해서, 먼저 2D CNN과 3D CNN 구조를 일반화 하였다. 이를 통해서, 오로지 다른 부분은 spatio-temporal module만 되도록 하였고, 모델간 객관적인 비교가 가능해 졌다. Figure 3 를 보면 우선 입력을 통일 하였다. 2D CNN은 TSN의 그것을 따랐고, 3D CNN은 3D Convolution을 위한 입력 shape을 따르고 있다. 입력 데이터는 Spatiotemporal module로 입력된다. 이 부분은 각 모델 구조마다 다르다. 이후 출력 벡터는 하나의 벡터가 될 수 도 있고 각 timestep마다 벡터가 나올 수도 있으므로 option으로 temporal pooling(avg pool)을 해줄 수 도 있다. 이후는 FC 레이어에 입력되어 action prediction이 되며, 하나의 비디오에 대해서 여러번 inference가 이루어질 경우 softmax score fusion 이 이루어 진다.
Datasets, Training, Evaluation Protocols
역시 공정한 비교를 위해서, 모두 같은 data processing, 같은 학습 절차, 같은 evaluation protocol로 학습했다.
Mini-Kinetics, Mini-SSV2 : 기존 데이터셋의 클래스중 랜덤하게 반을 선택
Mini-MiT : 공식 subset을 사용.
2. Training
학습시 사용한 프레임 수는
로 정의했다. 8, 16, 32, 64 프레임 까지 사용. starter 모델은 ImageNet pretrained weights로 초기화 된 뒤 8프레임을 사용해 학습되었다. 이후 16, 32, 64 프레임은 차례차례 이전 스케일의 학습된 모델로 초기화 된 뒤 파인튜닝 되었다.
3. Evaluation Protocol
Action Recognition을 위한 Evaluation protocol은 2가지가 존재한다. clip-level accuracy와 video-level accuracy 이다.
clip-level accuracy는 동영상 하나에 대해서 하나의 클립에 대해서만 평가하는 것이고, video level accuracy는 여러개의 클립에 대해서 나온 결과를 앙상블하는 evaluation protocol이다. 그래서 video-level accuracy가 일반적으로 clip-level accuracy보다 성능이 높다. 본 논문은 기본으로 clip-level accuracy로 스코어를 보고한다.
Experimental Results and Analysis
1. Performance Analysis on Mini Datasets
이 실험을 위해서 총 288번의 학습을 했다고 한다. (288epoch이 아니라 288개의 모델을 학습!) 3개의 백본(Inception V1, ResNet18, ResNet50)과 2개의 시나리오(temporal pooling의 유무), 4개의 프레임 개수 (8, 16, 32, 64)를 평가했다. 대부분의 세팅은 원 논문에서 수행되지 않았던 세팅이다.
*temporal pooling이 고려되지 못한 모델 구조의 경우에, temporal pooling이 오히려 성능저하를 가져올 수 있으므로, 논문의 저자들은 temporal pooling을 하지 않은 경우를 주로 참고하라고 이야기하고 있다.
1.1 Backbone 비교 실험
더 좋은 backbone 성능(이미지넷 성능)이 action recognition 에도 어느정도 linear하게 반영 되었다.
ResNet50 > Inception V1 > ResNet18 의 성능을 일반적으로 보여주고 있다.
Kinetics와 SSV2에서 ResNet50일 때 I3D 가 S3D 보다 전반적으로 성능이 높다.(사각형)
1.2 입력 프레임 수 비교 실험
입력 프레임 수가 늘어날 수록 성능이 향상됨을 알 수 있다. Moments in Times에서는 32프레임부터는 뚜렷한 성능 향상이 없음을 알 수 있다.
1.3 샘플링 방법 비교 실험
Sampling strategy는 크게 2가지가 존재한다. TSN에서 처음 제안된 Uniform sampling. 이 방법은 동영상을 몇개의 segment로 나누고 각 segment에서 대표 프레임을 하나씩 뽑아 쌓는 방법이다. 전체 프레임 수는 segment의 크기만큼 으로 결정된다. 보통 2D CNN에서 많이 사용하는 방법이다. Dense sampling은 3D CNN에서 많이 사용되는 방법으로 연속된 프레임을 연속적으로 샘플링하는 방법이다. 왜 이런 방법들이 각 구조에서 선호 되는지는 명확하지 않지만, 2D CNN에서 TSN이 차지하는 비중과 많은 코드들이 TSN의 코드를 기반으로 작성되었다는 점에서 Uniform sampling이 많이 사용되는 이유를 유추할 수 있다.
파란색 : Uniform Sampling
주황색 : Dense Sampling
Uniform sampling이 Dense sampling보다 성능이 띄어남을 알 수 있다. 이는 당연하게도, Dense sampling 방식은 스트라이드를 조절하더라도, 모든 시점의 데이터가 들어가지 못할 수 있다. 하지만 Uniform sampling은 적어도 모든 시점에서의 정보가 균일하게 입력에 포함되기는 한다. (이는 trimmed video를 대상으로 한 action recognition에서 중요한 점이다.)
옅은 색은 video-level accuracy를 의미한다. 즉 n개의 클립에 대해서 연산을 하고 이를 앙상블한 결과이다. 주로 segment 구성은 같이 하고 segment 의 대표 프레임은 랜덤하게 추출하는 방식을 사용한다. Uniform sampling 방식과 비교해서 Dense sampling에 multi clip 앙상블을 적용했을 때 비약적인 성능 향상이 존재함을 알 수 있다. 하지만, n개의 클립을 사용하면 inference time과 FLOPS도 n배 상승한 다는 단점이 존재한다. 이는 학습 시간을 n배로 증가시킨다. 본 논문에서는 이와같은 결과 분석을 통해서, 다음단계에서는 uniform sampling 과 clip-level evaluation 방법을 선택하였다.
주석 : 이는 하나의 클립으로 미쳐 보지 못한 다른 부분에 대한 고려가 포함되기 때문으로, 행동에는 하이라이트 부분이 존재한 다는 점, 즉 중요한 정보를 담고 있는 segment 가 있고 그렇지 않은 segment(행동의 시작과 끝 등)이 존재한다는 점에서 생각해 볼 수 있다. 특히 8프레임을 사용하고 있는 경우에는 이 효과가 더 커질 것이다.
1.4 Temporal pooling의 유무 비교 실험
그림이 accuracy가 아니라 accuracy gain 임에 유의하자
- Temporal Pooling은 일반적으로 3D CNN에서의 efficiency 향상을 위해 사용된다. stacking된 timestep의 개수를 줄여 주기 때문에 computational cost가 줄어든다.
- Temoral Pooling(특히 average pooling)은 일반적으로 모델 성능을 떨어트린다. 왜냐하면 정보의 손실 때문이다. Object Detection에서 연산 복잡도를 줄이기 위해서 Spatial pooling을 수행하면 성능이 떨어지는 것과 동일하다. 때문에 Slowfast network나 X3D 에서는 Temporal pooling을 사용하지 않고 다른 테크닉으로 computational cost를 줄였다.
Figure 6을 보면 알 수 있지만, Temporal Pooling 방식은 대부분의 구조에서 성능하락을 불러 일으켰다. 하지만 TSN에서는 놀랍게도 전반적으로 성능향상이 가능했다. 이에 전체 Kinetics 데이터셋으로 학습을 진행 한 결과 temporal pooling을 하지 않았을 때와 비교했을 때보다 5.1% 상승한 74.9%를 달성하였고, 이는 SOTA 모델과 비교해도 2% 정도 뒤진 것에 불과한 수치이다. 그러니까, Temporal pooling을 한다고 반드시 성능이 하락한다는 것은 잘못된 상식이다. 이에 논문저자들은 temporal pooling이 여러 프레임 간 정보를 교환할 수 있는 가장 간단한 방법들중 하나라고 이 결과를 해석하게 되었다. 다른 복잡한 temporal modeling 모듈을 가진 네트워크들에서는 효과가 반감되지만, Sampling strategy를 제외하고는 temporal modeling이라고 불리울만한 추가적인 장치가 부족한 TSN에서는 추가적인 성능향상이 가능한 방법인 것이다.
2. Benchmarking of SOTA Approaches
2.1 Results on Full Datasets
I3D-Inception V1은 지금까지 다양한 action recognition 논문에서 많이 베이스라인으로 사용되어 왔으나 성능 측정기 수준으로 머물렀으며 그 능력이 저평가 되어 왔다.
동일한 환경에서, 동일한 조건으로 학습했을 때. 같은 backbone에서 temporal pooling을 제거한 I3D-R50모델은 TAM-R50이나 slowfast-R50과 경쟁할만한 성능을 달성했으며, Kinetics에 대해서는 Squeeze and Excitation 모듈을 장착했을 때 오히려 slowfast보다 더 높은 성능을 달성했다. Temporal Pooling을 제거한 경우도 함께, 그리고 동일한 backbone에 대해서 모두 측정해야함을 시사한다. 또한 논문 저자들은 이러한 결과가 의미하는 바가 최근 제안된 모델들이 더 우수한 spatio-temporal modeling 능력이 있어서가 아니라 단지 더 좋은 백본을 사용했기 때문에 더 높은 성능을 달성할 수 있었음을 간접적으로 시사한다고 이야기 하고 있다.
Uniform Sampling vs Dense Sampling
I3D나 TAM 구조는 Sampling 방법에 큰 영향을 받지 않고 있으나, SlowFast는 Uniform Sampling을 할 때 성능이 5%정도 하락하였다.
주석 : 이는 SlowFast가 Two-Stream을 구성할 때 서로 다른 fps로 샘플링 하는 구조이기 때문인 것으로 보인다. Uniform Sampling을 하게 되면, 이런 샘플링 효과가 줄어들기 때문이다. 논문에서는 Efficiency를 위해서 설계된 two-stream 구조 때문이라고 설명하고 있다.
Sampling 방법과 clip inference 와의 관계
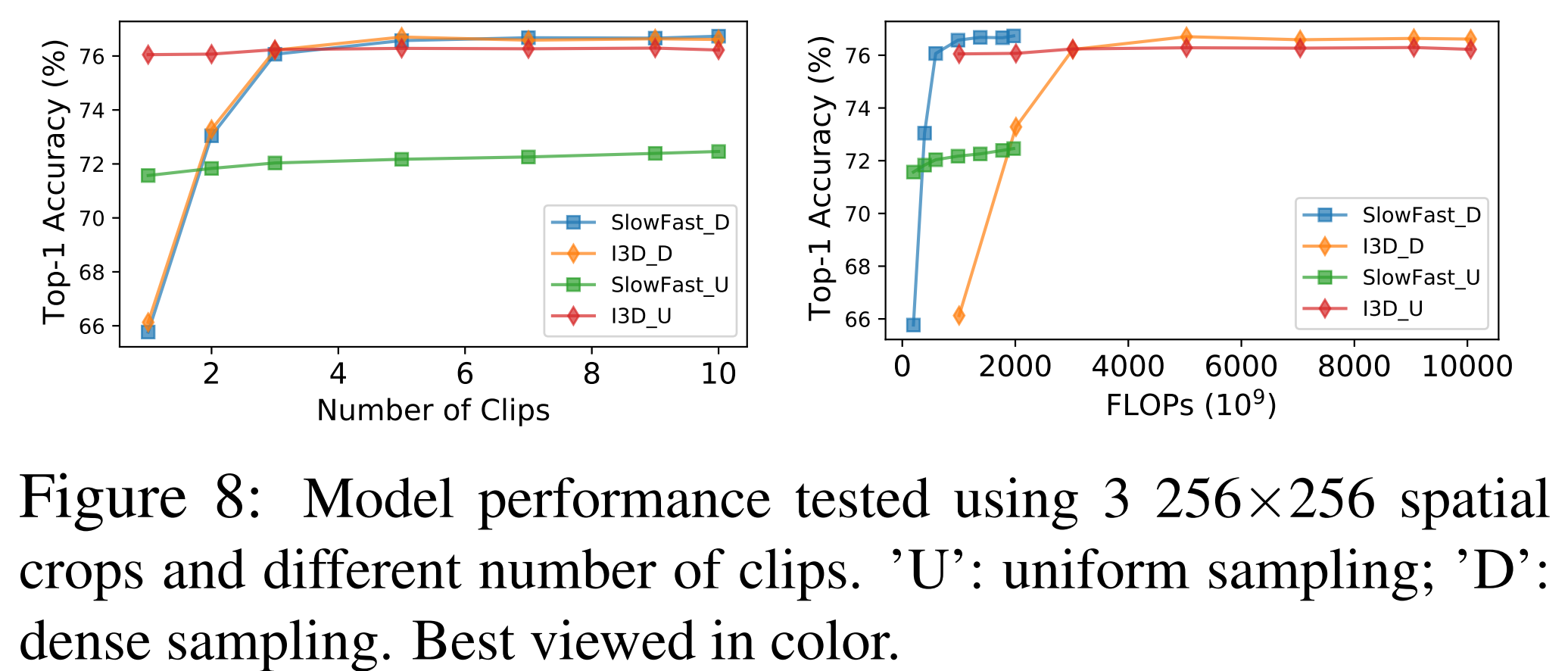
Figure 8을 살펴보면, Dense Sampling과 Uniform Sampling을 비교해 보았을 때, Dense Sampling이 Uniform Sampling 보다 성능이 더 높은 경향이 존재하며, Dense Sampling은 clip 수를 늘릴 때 성능향상 효과를 봄을 알 수 있다. 때문에 Sampling Strategy또한 evaluation factor 로서 포함 되어야 한다.또한 clip 수가 4개 이상일 때에는 성능 향상이 미미하여 trade-off로서 clip을 4개 정도 사용하는 것이 적당함을 알 수 있다. 현재 널리 사용되고 있는 10-clip evaluation 방식이 필요치 않음도 알 수 있다.
Model Transferability
Fine-tuning을 하여 model transferability도 실험 했다.
세 가지 모델 모두 downstream task(더 쉬운 데이터셋)에 대해서 서로 비슷한 성능을 보이고 있으며, I3D가 SOTA 모델인 TAM이나 SlowFast와 비교해서도 우월한 성능을 가진 경우가 있다. 이 결과로 다시한번 동일한 백본으로 비교해야 한다는 것이 중요함을 알게 되었다.
Analysis of Spatio-temporal Effects
일반적으로, Action Recognition task의 분류 성능이 높은 모델은 더 좋은 Spatio-temporal modeling 능력을 가지고 있다고 해석할 수 있으며, 때문에 SOTA 모델이 이전 모델들 보다 더 좋은 Spatio-temporal modeling 능력을 가지고 있다고 많은 논문들에서 주장한다.
하지만 앞서 언급하였지만, Kinetics 나 Moment in Times 와 같은 데이터셋들은 Temporal information이 없이도 행동을 분류할 수 있는 샘플들이 많이 포함되어 있다. 심지어 MiT 데이터셋에 대해서는 2D 모델이 3D 모델을 능가하는 성능을 보이기도 했다[27]. 논문 저자들은 Kinetics나 MiT 데이터셋을 "static"데이터셋으로 규정하며 해당 데이터셋 성능으로 최적화된 모델이 과연 더 나은 Spatio-temporal modeling을 가지고 있는지에 대한 의문을 제시한다.
Temporal Aggregation
Temporal modeling을 위해서는 각 시점의 데이터를 혼합해 주는 작업이 필요한데, 이것을 Temporal Aggregation 이라고 한다. 현재 Temporal aggregation은 다양한 구조가 제안되어 왔다. Temporal aggregation은 3D CNN에서는 필터 그자체에 시간축이 들어가기 때문에 가능하다. 물론 2D CNN에서도 가능하다. TSM처럼 Temporal shift를 해도 되고, S3D 처럼 1D temporal convolution을 추가해도 되고, TAM 처럼 1D depthwise convolution을 추가해도 된다. 또는 non-local 모듈을 추가해도 된다.
ResNet50의 결과를 보면, Temporal modeling이 중요한 SSV2 에서는 물론이고, Kinetics에서도 TAM이나 TSM, Non-local, 3D convolution 등 temporal aggregation이 들어간 모델의 성능이 좋음을 알 수 있다. 또한 여기서 한가지 더 알 수 있는 사실은, 아무 temporal aggregation을 하지 않았음에도 Kinetics에서의 성능은 72.1%나 되지만, SSV2에서는 33.9밖에 되지 못한 다는 것이다. 앞서 설명했던 내용을 뒷받침하는 결과이다. 또한, SSV2에서는 Non-local이 그리 효과적이지 못했다.
Locations of Temporal Modules
일반적으로, Temporal aggregation 은 한번의 feature learning 이후에 모듈식으로 이루어진다. 때문에 temporal aggregation module을 어디에 집어 넣을 것인가도 중요하다.
All : 모든 단계에서 aggregation
Top-half : top부분만 aggregation
Uniform-Half : 균일하게 반만 aggregation (한번씩 건너뛰기)
Bottom-Half : bottom부분만 aggregation
- Kinetics에서는 aggregation의 위치가 큰 영향이 없다.
주석 : Kinetics가 static 데이터셋임을 상기하자.
- SSV2에서는 TOP-half가 가장 높은 성능을 달성했다.
주석 : 먼저 Spatial feature extraction 을 하고 어느정도 학습된 feature를 뒷부분에서 aggregation 하는 것이 효율적이라는 것은 feature fusion에서 종종 언급되는 내용인데, temporal aggregation도 결국엔 각 시점에 대한 feature fusion이기 때문에 중요한 insight를 얻어갈 수 있었다.
Disentangling Spatial and Temporal Effects
앞서 기존 evaluation 방식의 문제점들을 다루어 보았다. 문제점을 제시했으면 해결책도 제시해야한다. 논문 에서는 spatial temporal modeling 능력이 실제 모델 성능에 미치는 영향을 수치화 하는 방법을 제안한다.
TSN은 TSM등 여러 temporal aggregation module의 베이스라인으로 쓰여왔다. 때문에 논문에서도 TSN을 베이스라인으로 삼았다. 우선 설정들에 대한 notation을 정의하였다.
a : architecture
b : backbone
k : 입력된 프레임수 (k 개)
S : top-1 accuracy
1. Spatial contribution
2가지 상황이 존재한다.
같은 백본을 사용할 때 비교대상이 된 architecture a가 베이스라인인 TSN보다 성능이 높은 경우, 즉
1. S_a > S_TSN
Pi_a = S_TSN / S_a
1보다 작아지게 된다.
같은 백본을 사용할 때 비교대상이 된 architecture a가 베이스라인인 TSN보다 성능이 낮은 경우, 즉
2. S_a < S_TSN
Pi_a =S_TSN /S_TSN
1이 된다.
Pi가 0에 가까워 질 수록, 현재 성능에 대한 architecture a의 기여도가 높다.
수치가 작아질 수록, 제안된 모델에서 Spatialmodeling의 기여도가 줄어든다.
즉 수치가 작을 수록 제안된 모델의 temporal modeling 능력이 좋다고 할 수 있다!
2. Temporal improvement of model
분모는 고정이다. 이역시 2가지 경우가 존재한다. 베이스라인 성능에서 향상될 수 있는 수치(100-S_TSN)에 대한 성능향상이 이루어진 수치(S_a - S_TSN)의 비율이다.
1. S_a > S_TSN
Psi_a > ()
2. S_a < S_TSN
Psi_a < ()
Psi가 음수가 나오게 된다면, temporal aggregation module이 오히려 모델의 성능을 상하게 한 것이다.
이를 사용 가능한 모든 Backbone과 프레임 수에 대해서 평균 낸 수치는 위와 같이 계산된다.
본 논문에서 사용한 파라미터 들은 다음과 같다.
3개의 모델(I3D, S3D, TAM)이 모두 유사한 경향을 보이고 있다.
- Pi가 Psi보다 Mini SSV2에서 약간 더 높다.
- Pi가 Psi보다 Mini Kinetics에서 매우 높다.
- Pi가 Psi보다 Mini MiT에서 매우 높다.
> Kinetics나 MiT가 Spatial Modeling 능력이 Temporal Modeling 능력보다 훨씬 중요함을 알 수 있다. 이는 앞선 실험결과에서 별다른 Temporal Modeling 방법이 들어가지 않았던 TSN이 Kinetics에서 비교적 높은 성능을 달성했지만 SSV에서 매우 낮은 성능을 내었던 이유와 직결된다.
- temporal pooling을 temporal aggregation 과 함께 적용했을 때 Psi가 감소한다.